


最近OpenAI的ChatGPT真的是到处都在刷屏,我想你已经看过很多关于ChatGPT的文章或者视频了,我就不过多介绍了。
不过你碰巧还不知道的话,可以先百度一下,然后再回来继续。

与ChatGPT对话很有趣,甚至很有启发性。有人用它聊天,有人用它写代码,太多省时省力的工作,都可以由它完成,我们的内容创作部门已经将ChatGPT用于文案生成。那么对研发,ChatGPT是否有用呢?我做了一个测试,让ChatGPT来完成算法研究中频繁要做的数据清洗和处理问题,结果让人非常满意,以后还招啥工程师,直接找ChatGPT吧!

简单数据处理
我们首先从简单的任务入手,让ChatGPT完成数据加载和简单的清洗工作。
任务目标
- 加载数据集;
- 确保数据集中所有值均为数值类型,如果不是则尝试将其转换为数值类型;
- 检查缺失值;
- 数据集分成训练集和测试集。
上面这4个任务是算法执行前必须要做的常规工作。我们看一下ChatGPT的表现
输出结果
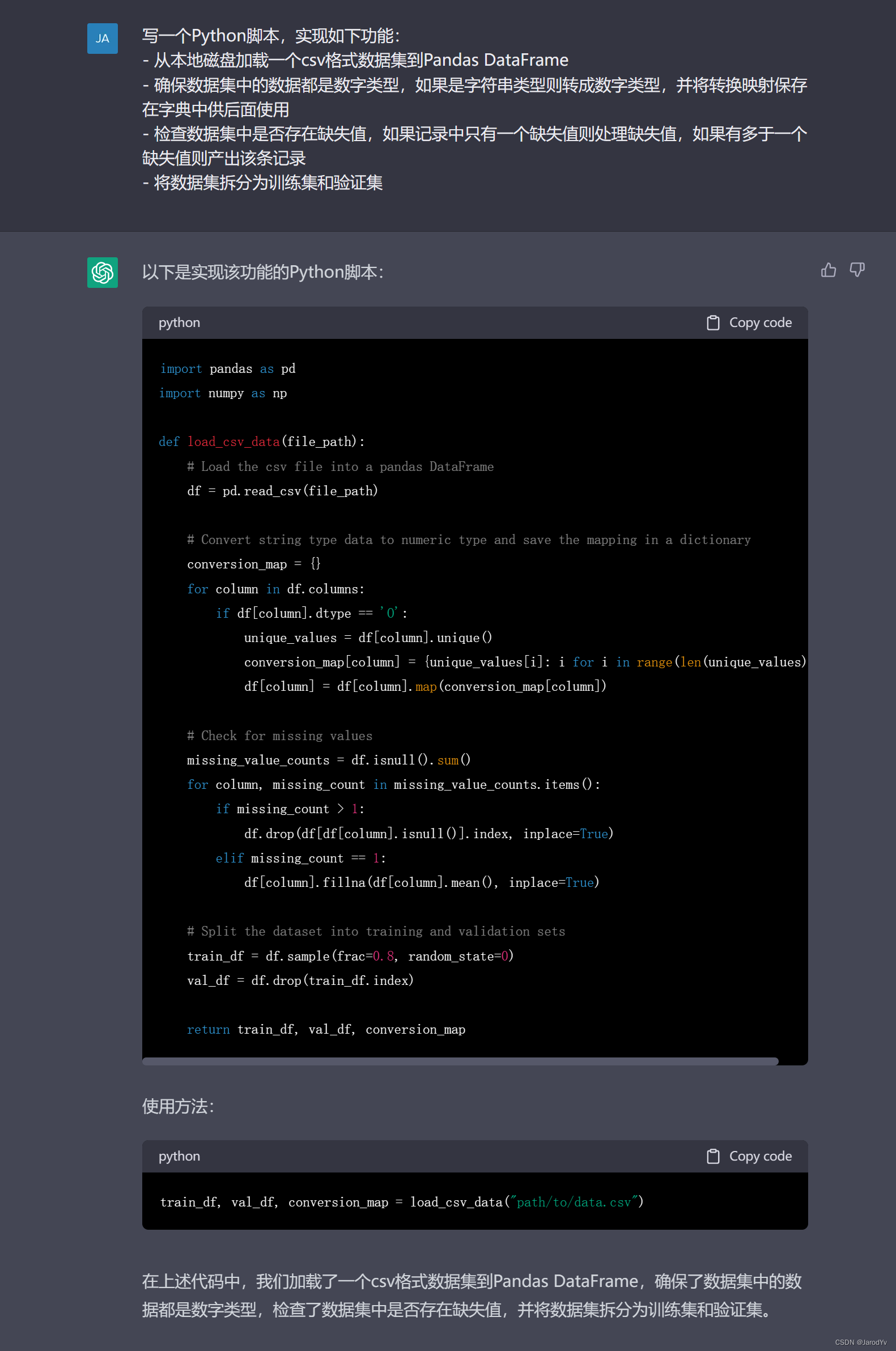
import pandas as pdimport numpy as npdef load_csv_data(file_path): # Load the csv file into a pandas DataFrame df = pd.read_csv(file_path) # Convert string type data to numeric type and save the mapping in a dictionary conversion_map = {} for column in df.columns: if df[column].dtype == 'O': unique_values = df[column].unique() conversion_map[column] = {unique_values[i]: i for i in range(len(unique_values))} df[column] = df[column].map(conversion_map[column]) # Check for missing values missing_value_counts = df.isnull().sum() for column, missing_count in missing_value_counts.items(): if missing_count > 1: df.drop(df[df[column].isnull()].index, inplace=True) elif missing_count == 1: df[column].fillna(df[column].mean(), inplace=True) # Split the dataset into training and validation sets train_df = df.sample(frac=0.8, random_state=0) val_df = df.drop(train_df.index) return train_df, val_df, conversion_map# 新的一年,必须卷死同学、同事,狠狠的提升一波自己的Python实力。# 这里我给大家准备了2023最新的Python学习资料、电子书、基础视频教程、实战案例,直接在这个扣裙自取即可(708525271)
分析
上面代码可以完美完成目标任务,从csv文件中加载数据集,并以80/20的比例将数据集拆分为测试集和训练集,关键逻辑还加上了注释,ChatGPT甚至贴心的给出了函数使用方法。
ChatGPT生成上面代码总共用时116秒,同时我们的数据工程师编写同样功能的代码用时225秒。二者的代码差异不大,但是我们的数据工程师没写注释。
上面的任务是数据工程师几乎天天都要写的代码,他们很熟练。我又找了一个大学刚毕业还在实习期的数据助理来写,居然半个小时才完成,由于对接口不熟悉,大量时间花在了百度上[捂脸]。
第一轮比试,从各个维度上,都是ChatGPT胜。
重构代码
在上一轮的比试中,我发现我们的数据工程师有“偷鸡”行为——由于平时经常需要完成上面工作,他将很多功能封装成了独立的函数,用的时候直接引入或拷贝。使用函数按照逻辑组织代码,不仅能够促进代码复用,还有利于代码维护。所以我们接下来试着让ChatGPT重构一下自己的代码。
任务目标
将上面的代码按照功能合理地拆分成若干函数。
输出结果

import pandas as pdimport numpy as npdef load_csv(file_path): return pd.read_csv(file_path)def convert_strings_to_numeric(df): conversion_map = {} for column in df.columns: if df[column].dtype == 'O': unique_values = df[column].unique() conversion_map[column] = {unique_values[i]: i for i in range(len(unique_values))} df[column] = df[column].map(conversion_map[column]) return df, conversion_mapdef handle_missing_values(df): missing_value_counts = df.isnull().sum() for column, missing_count in missing_value_counts.items(): if missing_count > 1: df.drop(df[df[column].isnull()].index, inplace=True) elif missing_count == 1: df[column].fillna(df[column].mean(), inplace=True) return dfdef split_data(df): train_df = df.sample(frac=0.8, random_state=0) val_df = df.drop(train_df.index) return train_df, val_dfdef prepare_data(file_path): df = load_csv(file_path) df, conversion_map = convert_strings_to_numeric(df) df = handle_missing_values(df) train_df, val_df = split_data(df) return train_df, val_df, conversion_map
分析
ChatGPT拆分出5个函数:
- load_csv(file_path) 负责从csv文件中加载数据集,返回DataFrame;
- convert_strings_to_numeric(df) 负责将DataFrame中的非数值类型数据转换为数值类型,并记录转换映射表;
- handle_missing_values(df) 负责处理缺失值;
- split_data(df) 负责将数据集拆分为训练集和测试集;
- prepare_data(file_path) 将上面4给函数串起来,构成一个pipeline。
不得不说,ChatGPT有一次完美地完成了任务!并且函数名起得非常好,看函数名就能知道函数的功能,比很多中国程序员用拼音或缩写命名函数友好多了。
扩展代码
重构后的代码结构已经非常清晰了,但是还是有缺陷,那就是不够灵活,很多规则都是写死的。为了让代码更灵活、可扩展性更强,我们一般会将变量以参数的形式传入。
任务目标
重构上面的代码,以参数的形式从命令行传入以下内容:
- csv格式数据集的路径
- 拆分训练集和验证集的大小
- 阈值,缺失值大于此阈值则删除记录,小于等于此阈值则处理缺失值
输出结果
import pandas as pdimport numpy as npimport argparsedef load_csv(file_path): return pd.read_csv(file_path)def convert_strings_to_numeric(df): conversion_map = {} for column in df.columns: if df[column].dtype == 'O': unique_values = df[column].unique() conversion_map[column] = {unique_values[i]: i for i in range(len(unique_values))} df[column] = df[column].map(conversion_map[column]) return df, conversion_mapdef handle_missing_values(df, threshold): missing_value_counts = df.isnull().sum() for column, missing_count in missing_value_counts.items(): if missing_count > threshold: df.drop(df[df[column].isnull()].index, inplace=True) elif missing_count <= threshold: df[column].fillna(df[column].mean(), inplace=True) return dfdef split_data(df, split_ratio): train_df = df.sample(frac=split_ratio, random_state=0) val_df = df.drop(train_df.index) return train_df, val_dfif __name__ == "__main__": parser = argparse.ArgumentParser(description='Prepare data for machine learning.') parser.add_argument('file_path', help='Path to the csv file.') parser.add_argument('--split-ratio', type=float, default=0.8, help='Ratio of the training set size.') parser.add_argument('--threshold', type=int, default=1, help='Threshold for handling missing values.') args = parser.parse_args() df = load_csv(args.file_path) df, conversion_map = convert_strings_to_numeric(df) df = handle_missing_values(df, args.threshold) train_df, val_df = split_data(df, args.split_ratio)
分析
ChatGPT很好地理解了我们的意图,引入了argparse模块来管理和解析命令行参数,关键是参数名起的也非常合理,参数说明也非常准确(尽管是英文的)。参数都正确地传入了所属的函数,又一次完美的完成了任务。
总结
ChatGPT根据我们提供的规范,在创建、重构、扩展一个简单的数据预处理Python脚本方面做得非常出色,每一步的结果都符合要求。虽然这不是一个复杂任务,确实日常工作中最常见的基本工作。ChatGPT的表现确实惊艳了众人,预示着它朝着成为真正有用的编程助手迈出重要的一步。
最终我们从如下几个方面将ChatGPT和我们的数据工程师做了对比:

可见ChatGPT在编码速度和编码习惯上都完胜人类工程师。这让我不得不开始担心程序员未来的饭碗。是的,你没有看错!程序员这个曾经被认为是最不可能被AI取代的职业,如今将面临来自ChatGPT的巨大挑战。根据测试,ChatGPT已经通过Google L3级工程师测试,这意味着大部分基础coding的工作可以由ChatGPT完成。尽管ChatGPT在涉及业务的任务上表现不佳,但未来更可能的工作方式是架构师或设计师于ChatGPT协同完成工作,不再需要编码的码农。